4 Exploring categorical data
This chapter focuses on exploring categorical data using summary statistics and visualizations. The summaries and graphs presented in this chapter are created using statistical software; however, since this might be your first exposure to the concepts, we take our time in this chapter to detail how to create them. Where possible, we present multivariate plots; plots that visualize the relationship between multiple variables. Mastery of the content presented in this chapter will be crucial for understanding the methods and techniques introduced in the rest of the book.
In this chapter, we will introduce tables and other basic tools for organizing and analyzing categorical data that are used throughout this book. Table 4.1 displays the first six rows of the email data set containing information on 3,921 emails sent to David Diez’s Gmail account (one of the authors of the OpenIntro textbooks). In this section we will examine whether the presence of numbers, small or large, in an email provides any useful value in classifying email as spam or not spam.
Descriptions of all five email variables are given in Table 4.2.
The email data can be found in the openintro package: email.
Load these data into your RStudio session using the following commands:
library(openintro)data(email)
| type | num_char | line_breaks | format | number | |
|---|---|---|---|---|---|
| 1 | not spam | 11.37 | 202 | HTML | big |
| 2 | not spam | 10.50 | 202 | HTML | small |
| 3 | not spam | 7.77 | 192 | HTML | small |
| 4 | not spam | 13.26 | 255 | HTML | small |
| 5 | not spam | 1.23 | 29 | not HTML | none |
| 6 | not spam | 1.09 | 25 | not HTML | none |
| variable | description |
|---|---|
| type | Whether the email was spam or not spam. |
| num_char | The number of characters in the email, in thousands. |
| line_breaks | The number of line breaks in the email (does not count text wrapping). |
| format | Whether the email was written using HTML (e.g., may have included bolding or active links) or not. |
| number | Categorical variable saying whether there was no number, a small number (under 1 million), or a big number. |
4.1 Contingency tables and conditional proportions
A summary table for a single categorical variable that reports the number of observations (frequency) in each category is called a frequency table. Table
4.3 is a frequency table for the number variable.
If we replaced the counts with percentages or proportions (relative frequencies),
the table would be called a relative frequency table.
| none | small | big |
|---|---|---|
| 549 | 2827 | 545 |
Table 4.4 summarizes two variables:
type (spam or not spam) and number. A table that summarizes data for two categorical variables
in this way is called a contingency table or two-way table.
Each value in the table represents the number of times, or frequency
a particular combination of variable outcomes occurred.
For example, the value 149 corresponds to the number of emails
in the data set that are not spam and had no number listed in the email.
Row and column totals are also included.
The row totals provide the total counts across each row
(e.g., there are \(149 + 168 + 50 = 367\) emails classified as not spam), and column totals are total
counts down each column.
In this textbook, we generally take the convention of putting the categories of the explanatory variable as the columns and the categories of the response variable as the rows (if there exists and explanatory-response relationship between the two variables).
| none | small | big | Total | ||
|---|---|---|---|---|---|
| spam | 400 | 2659 | 495 | 3554 | |
| type | not spam | 149 | 168 | 50 | 367 |
| Total | 549 | 2827 | 545 | 3921 |
We would like to examine whether the presence of numbers—none, small or large—in an email provides any useful value in classifying email as spam or not spam—that is, is there an association between the variables number and type?
To determine if a relationship exists between whether an email is spam or not, and whether the email has no numbers, a small number, or a big number, why isn’t it helpful to compare the number of spam emails across the number categories?28
The proportion of emails that were classified as spam in the data set is \(3554/3921 = 0.906\), or about 91%. Let’s compare this unconditional proportion to the conditional proportions of spam within each number category: \(400/549 \approx 73\%\) of emails with no numbers are spam; \(2659/2827 \approx 94\%\) of emails with small numbers are spam; and \(495/545 \approx 91\%\) of emails with big numbers are spam. Since these three conditional proportions differ, we say the variables number and type are associated in this data set. Note that some differ from the overall, or unconditional, proportion of spam emails in the data set—91%.
Association between two categorical variables.
An unconditional proportion is a proportion measured out of the total sample size. A conditional proportion is a proportion measured out of a subgroup in the sample.
If the conditional proportions of a particular outcome (e.g., spam email) within levels of a categorical variable (e.g., whether no number, a small number, or a big number appears in the email) differ across levels, we say those two variables are associated. We can also determine if two categorical variables are associated by checking if any of the conditional proportions of the outcome within categories differ from the overall, or unconditional proportion.
4.1.1 Row and column proportions
Conditional proportions that condition on a row category are called row proportions; conditional proportions that condition on a column category are called column proportions.
Table 4.5 shows the row proportions for Table 4.4. The row proportions are computed as the counts divided by their row totals. The frequnecy 149 at the intersection of not spam and none is replaced by \(149/367=0.406\), i.e., 149 divided by its row total, 367. So what does 0.406 represent? It corresponds to the conditional proportion of non-spam emails in the sample that do not have any numbers.
| none | small | big | |
|---|---|---|---|
| spam | 0.113 | 0.748 | 0.139 |
| not spam | 0.406 | 0.458 | 0.136 |
A contingency table of the column proportions is computed in a similar way, where each column proportion is computed as the count divided by the corresponding column total. Table 4.6 shows such a table, and here the value 0.729 indicates that 72.9% of emails with no numbers were spam. This rate of spam is much lower than emails with only small numbers (94.1%) or big numbers (90.8%). Because these spam rates vary between the three levels of number (none, small, big), this provides evidence that the spam and number variables are associated in this data set.
| none | small | big | |
|---|---|---|---|
| spam | 0.729 | 0.941 | 0.908 |
| not spam | 0.271 | 0.059 | 0.092 |
What does 0.139 at the intersection of not~spam and big represent in Table 4.5? What does 0.908 represent in the Table 4.6?30
Data scientists use statistics to filter spam from incoming email messages. By noting specific characteristics of an email, a data scientist may be able to classify some emails as spam or not spam with high accuracy.
One of those characteristics is whether the email contains no numbers, small numbers, or big numbers. Another characteristic is whether or not an email has any HTML content. A contingency table type and format variables from the email data set are shown in Table 4.7. Recall that an HTML email is an email with the capacity for special formatting, e.g., bold text. In Table~ 4.7, which would be more helpful to someone hoping to classify email as spam or regular email: row or column proportions?
Such a person would be interested in how the proportion of spam changes within each email format. This corresponds to column proportions: the proportion of spam in plain text emails and the proportion of spam in HTML emails.
If we generate the column proportions, we can see that a higher fraction of plain text emails are spam (\(209/1195 = 17.5\%\)) than compared to HTML emails (\(158/2726 = 5.8\%\)). This information on its own is insufficient to classify an email as spam or not spam, as over 80% of plain text emails are not spam. Yet, when we carefully combine this information with many other characteristics, such as and other variables, we stand a reasonable chance of being able to classify some email as spam or not spam.
| not HTML | HTML | Total | |
|---|---|---|---|
| spam | 209 | 158 | 367 |
| not spam | 986 | 2568 | 3554 |
| Total | 1195 | 2726 | 3921 |
The previous Example points out that row and column proportions are not equivalent. Before settling on one form for a table, it is important to consider each to ensure that the most useful table is constructed.
4.1.2 Sample proportions and population proportions
In the field of statistics, summary measures that summarize a sample of data are called statistics. Numbers that summarize an entire population are called parameters. You can remember this distinction by looking at the first letter of each term:
Statistics summarize Samples.
Parameters summarize Populations.
Proportions calculated from a sample of data are denoted by \(\hat{p}\). In our example, we were interested in the proportion of spam emails in our data set, so we could denote this by \(\hat{p} = 0.91\). If there are different groups we want to summarize with a proportion, we can add subscripts: \(\hat{p}_{none} = 0.73\), \(\hat{p}_{small} = 0.94\), and \(\hat{p}_{big} = 0.91\). Each of these values is a statistic since it is computed from a sample of data.
These 3921 emails were a sample from a larger group of emails—all emails that are sent to David Diez, either in the past or in the future. This larger group of emails is the population. There is some unknown value for the proportion of all emails in the population that would be classified as spam, which we denote by \(\pi\). Similarly, there are unknown values for the proportion of all emails with no numbers in the population that would be classified as spam, denoted by \(\pi_{none}\). Each of these unknown values are called parameters.
We typically use Roman letters to symbolize statistics (e.g., \(\bar{x}\), \(\hat{p}\)), and Greek letters to symbolize parameters (e.g., \(\mu\), \(\pi\)). Since we rarely can measure the entire population, and thus rarely know the actual parameter values, we like to say, “We don’t know Greek, and we don’t know parameters!”
4.2 Bar plots and mosaic plots
A bar plot is a common way to display a single categorical variable. The left panel of Figure 4.1 shows a bar plot for the number variable.
In the right panel, the counts are converted into proportions (e.g., \(549/3921=0.140\) for none).
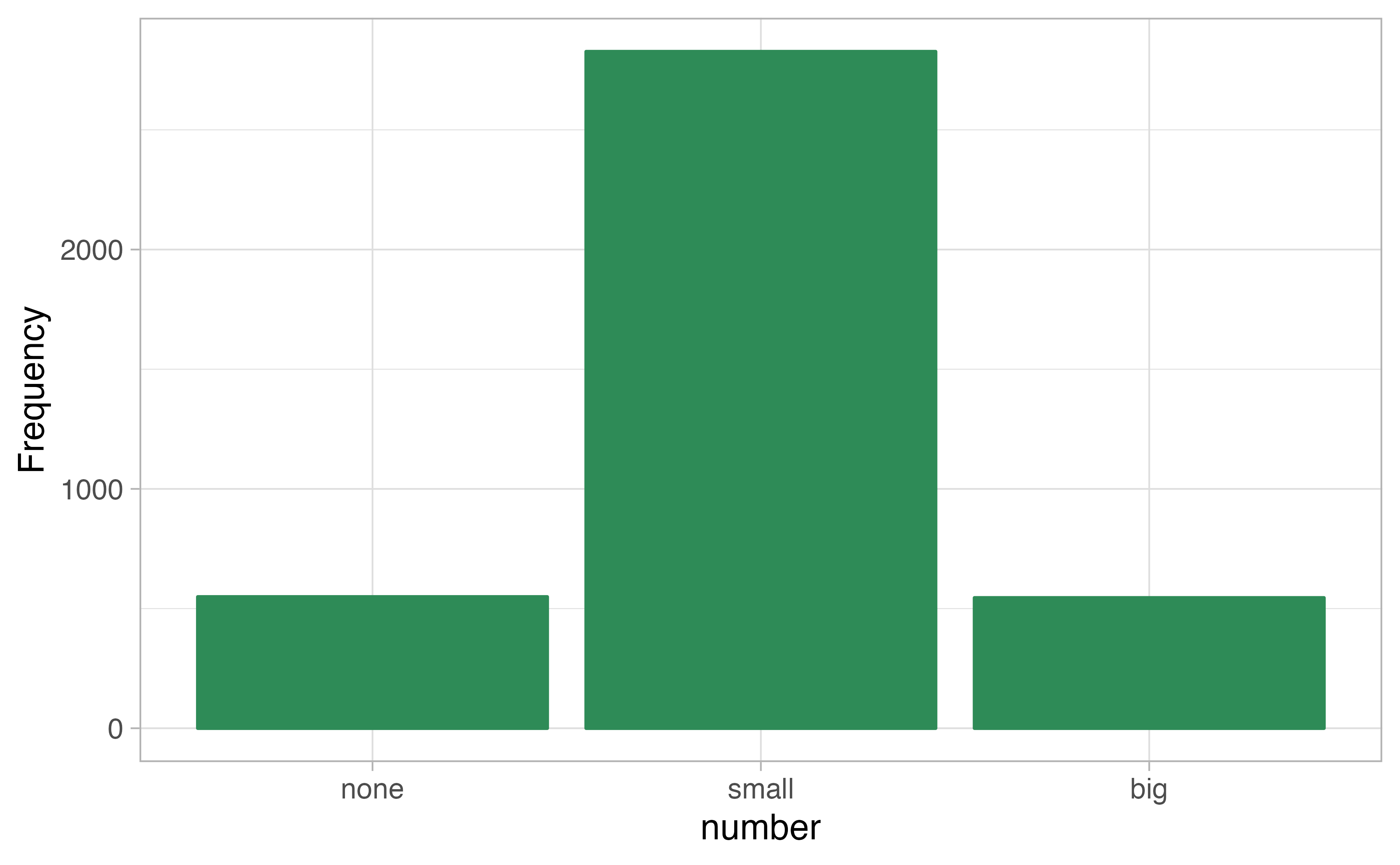
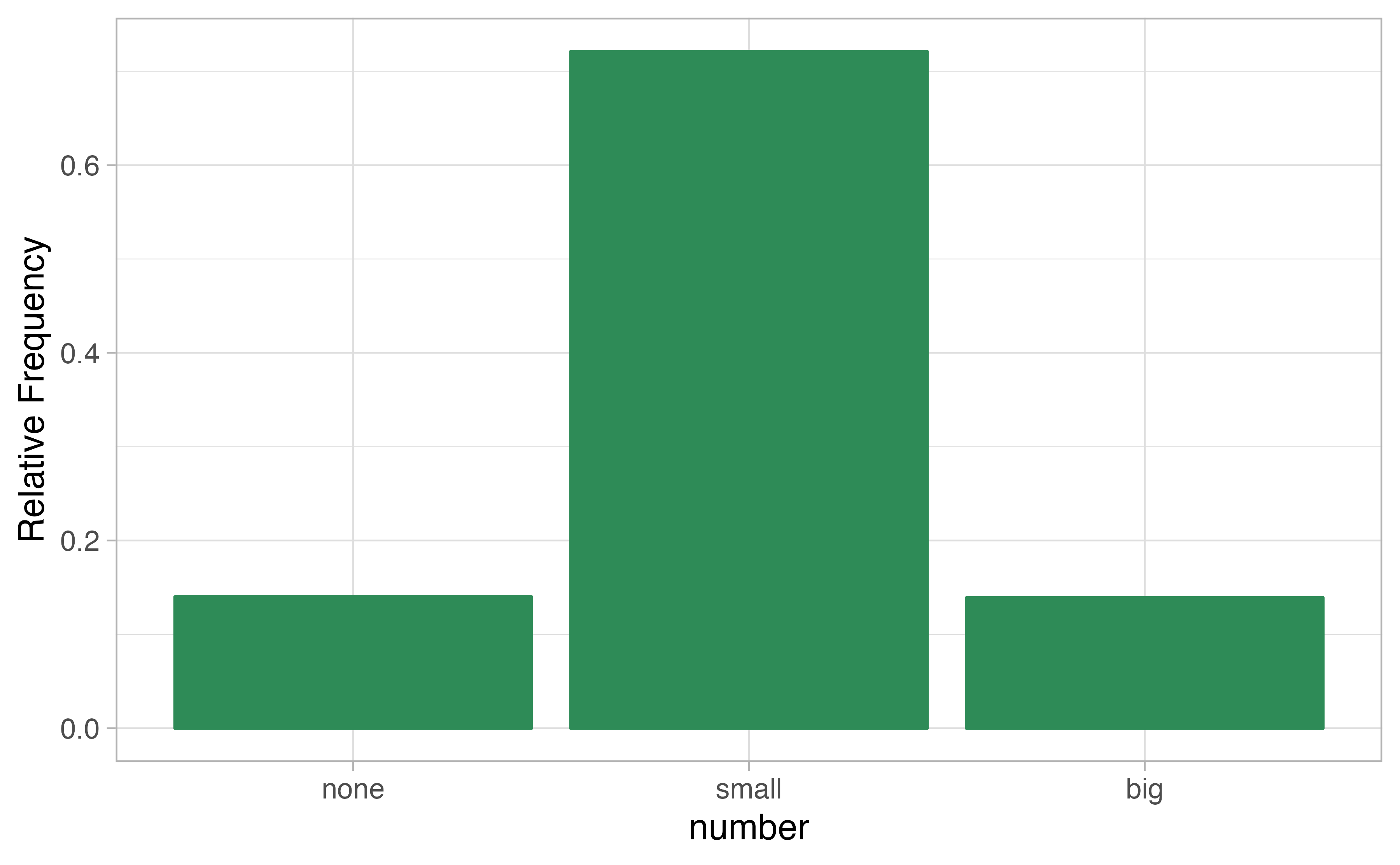
Figure 4.1: Two bar plots of number. The left panel shows the counts on the \(y\)-axis, and the right panel shows the proportions in each group on the \(y\)-axis.
Bar plots are also used to display the relationship between two categorical variables. When the bars are stacked such that each bar totals 100% and is segmented by another categorical variable, it is called a segmented bar plot.
A segmented bar plot is a graphical display of contingency table information. For example, segmented bar plots representing Table 4.6 is shown in Figure 4.2, where we have first created a non-standardized segmented bar plot using the number variable and then separated each group by the levels of type. The standardized segmented bar plot using the column proportions of Table 4.6 is a helpful visualization of the fraction of spam emails in each level of number.
In a segmented bar plot, the explanatory variable is plotted on the \(x\)-axis, while the response variable is displayed by different colors within each bar, defined by the legend.
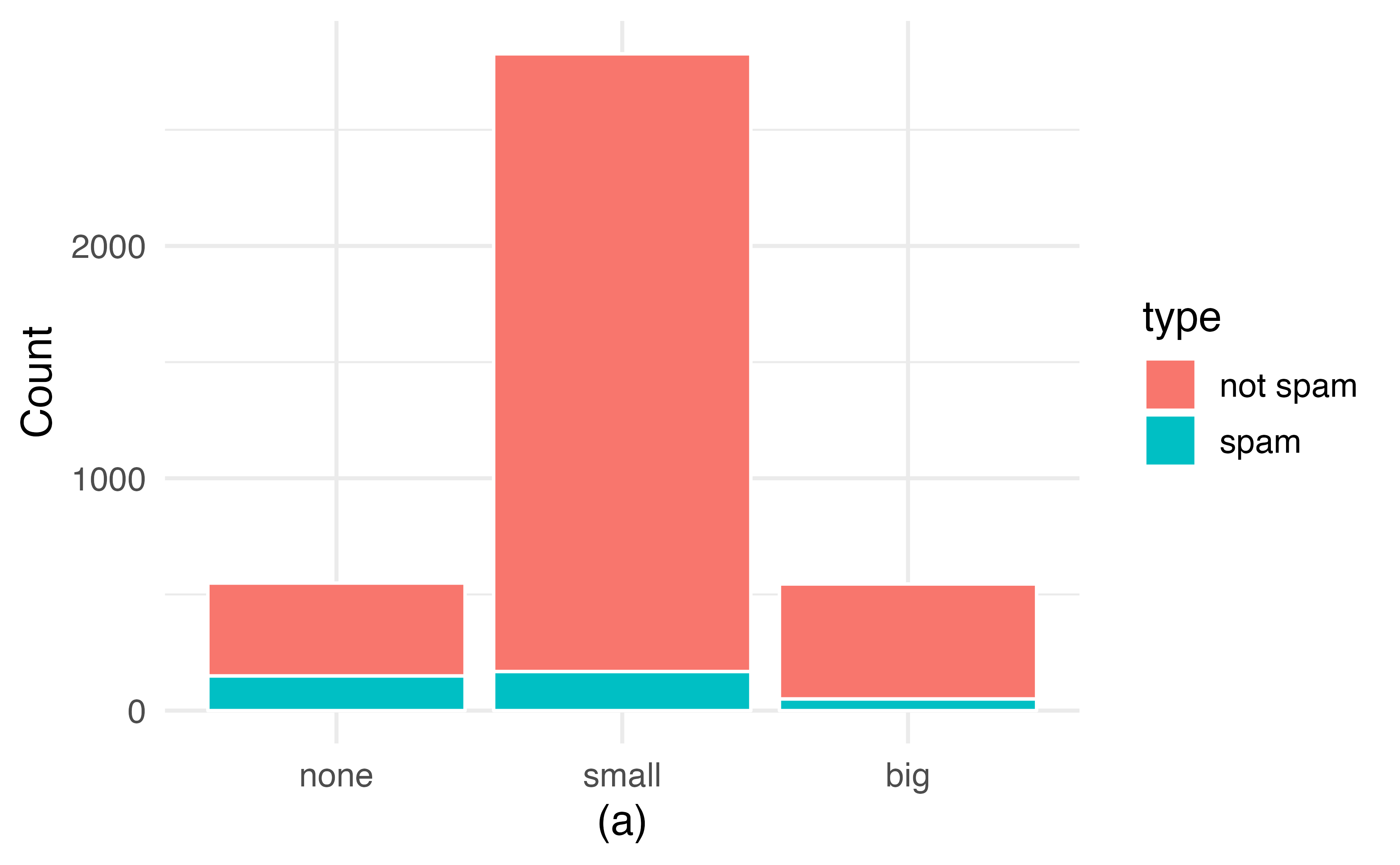
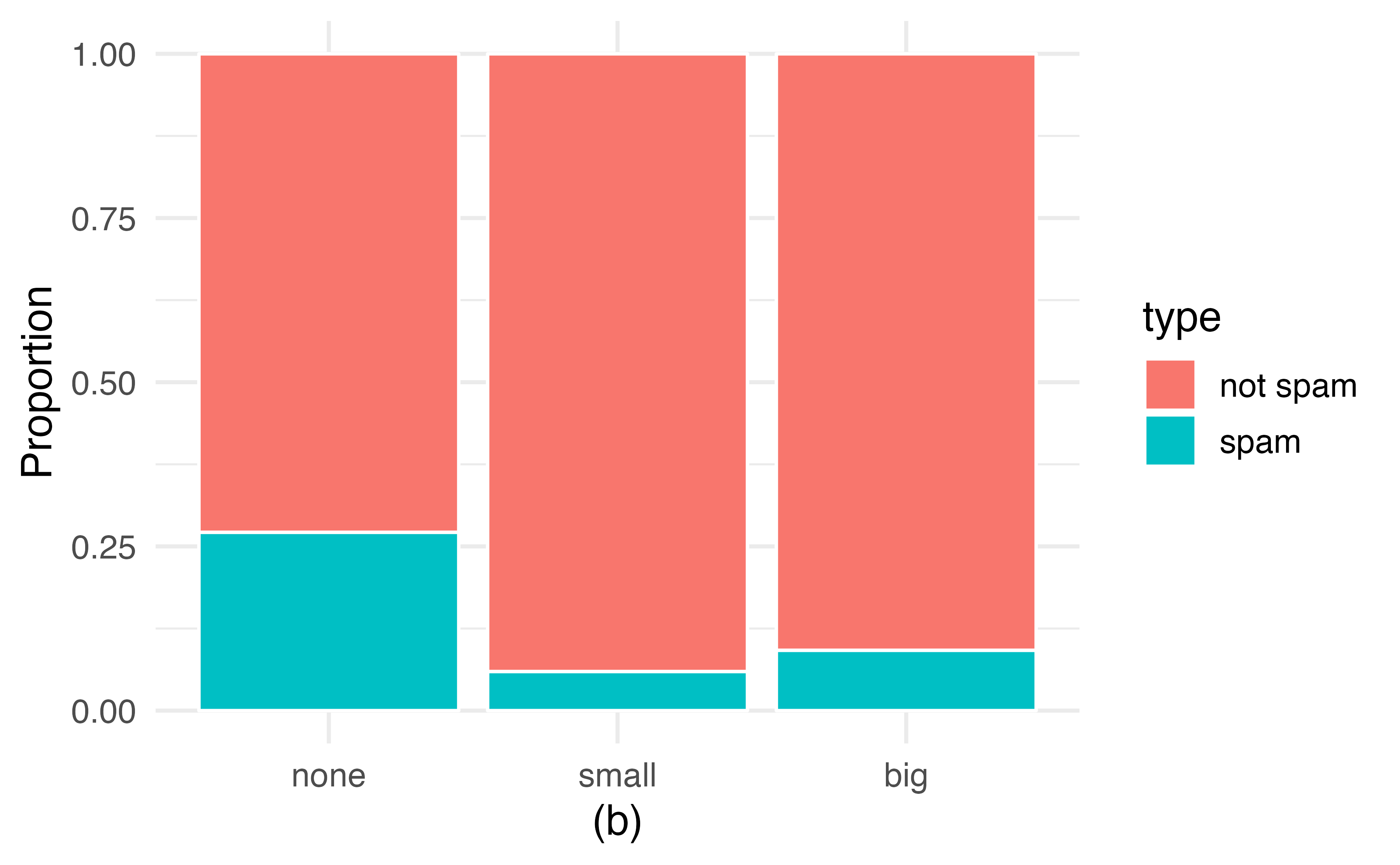
Figure 4.2: (a) Segmented bar plot for numbers found in emails, where the counts have been further broken down by type. (b) Segmented bar plot using column proportions of each type within each number category.
In the segmented bar plots in Figure 4.2, which variable is the explanatory variable? the response variable?32
Examine both of the segmented bar plots in Figure 4.2. Which is more useful?
Plot (a) contains more information, but plot (b) presents the information more clearly. Plot (b) makes it clear that emails with no number have a relatively high rate of spam email—about 27%! On the other hand, less than 10% of email with small or big numbers are spam.
Since the proportion of spam changes across the groups in Figure 4.2 (seen in plot (b)), we can conclude the variables are dependent, which is something we were also able to discern using the column proportions in Table 4.6. Because both the none and big groups have relatively few observations compared to the small group, the association is more difficult to see in plot (a) of Figure 4.2.
In some other cases, a segmented bar plot that is not standardized will be more useful in communicating important information. Before settling on a particular segmented bar plot, create standardized and non-standardized forms and decide which is more effective at communicating features of the data.
4.2.1 Mosaic plots
A mosaic plot is a graphical display of contingency table information that is similar to a bar plot for one variable or a segmented bar plot when using two variables. Figure 4.3 plot (a) shows a mosaic plot for the number variable. Each column represents a level of number, and the column widths correspond to the proportion of emails of each number type. For instance, there are fewer emails with no numbers than emails with only small numbers, so the no number email column is slimmer. In general, mosaic plots use box areas to represent the number of observations.

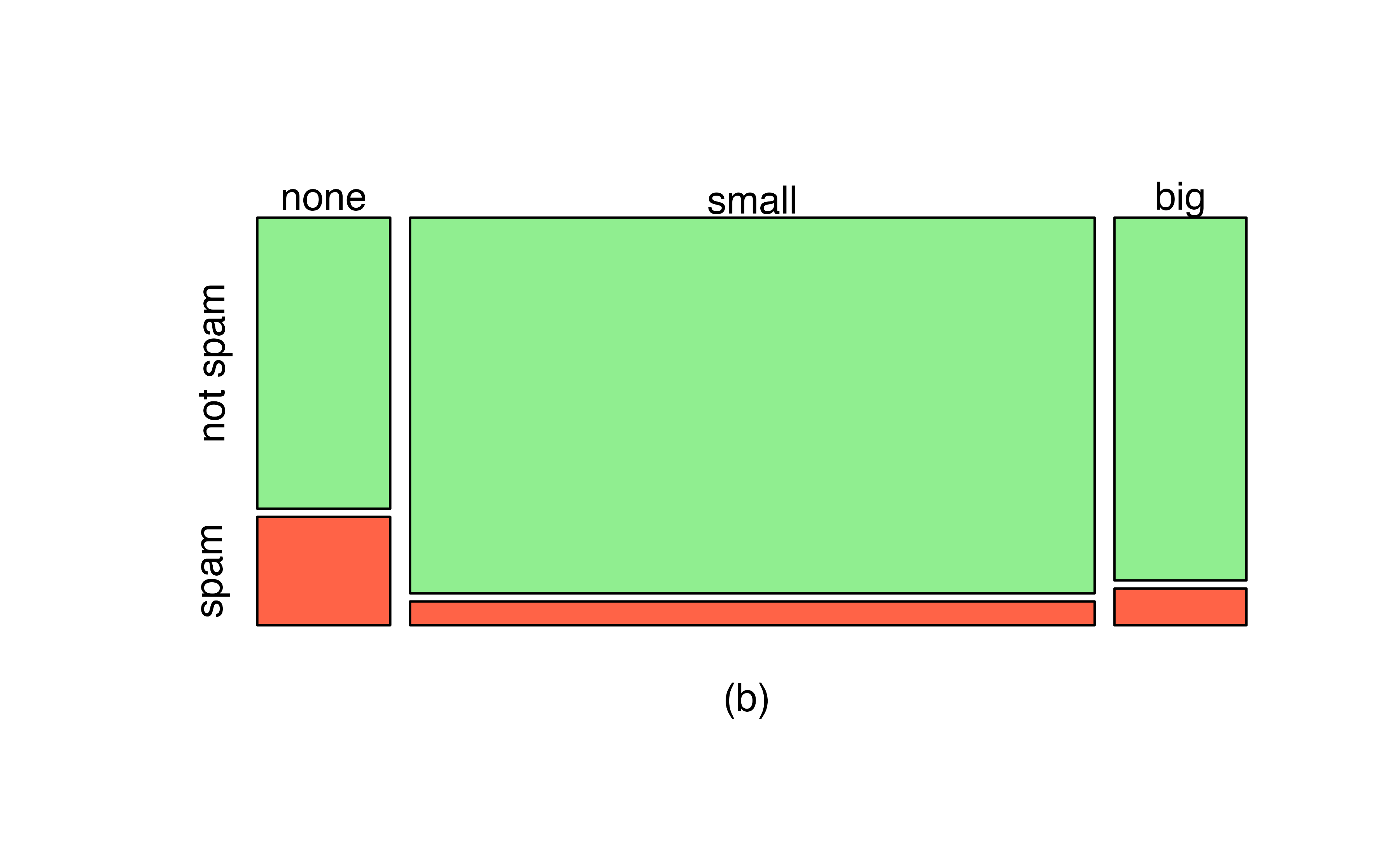
Figure 4.3: (a) Mosaic plot for numbers found in emails. (b) Mosaic plot where the number counts have been further broken down by type.
This one-variable mosaic plot is further divided into pieces in Figure 4.3 plot (b) using the type variable. Each column is split proportionally according to the fraction of emails that were spam in each number category. For example, the second column, representing emails with only small numbers, was divided into emails that were spam (lower) and not spam (upper).
As another example, the bottom of the third column represents spam emails that had big numbers, and the upper part of the third column represents regular emails that had big numbers. We can again use this plot to see that the type and number variables are associated since some columns are divided in different vertical locations than others, which was the same technique used for checking an association in the standardized version of the segmented bar plot.
As in a segmented bar plot, the explanatory variable is plotted on the \(x\)-axis of a mosaic plot, i.e., the explanatory variable is represented by columns, while the response variable is displayed by different colors within each column, defined by the legend.
4.3 Why not pie charts?
While pie charts are well known, they are not typically as useful as other charts in a data analysis. A pie chart is shown in Figure 4.4 alongside a bar plot. It is generally more difficult to compare group sizes in a pie chart (comparing angles) than in a bar plot (comparing heights), especially when categories have nearly identical counts or proportions. In the case of the none and big categories, the difference is so slight you may be unable to distinguish any difference in group sizes for either plot!
Figure 4.4: A pie chart and bar plot of number for the email data set. This is the only pie chart you will see in this book!
Pie charts are nearly useless when trying to compare two categorical variables, as is shown in Figure 4.5.
![Try comparing the distributions of colors across pie charts A, B, and C---it's impossible!^[R code from User:Schutz for Wikipedia on 28 August 2007]](04-explore-categorical_files/figure-html/worst-pie-chart-1.png)
Figure 4.5: Try comparing the distributions of colors across pie charts A, B, and C—it’s impossible!33
If you’re still not convinced that you shouldn’t use pie charts, read “The Issue with Pie Chart” on the “from Data to Viz” blog, and “The Worst Chart in the World” article on Business Insider.
4.4 Simpson’s paradox
A 1991 study by Radelet and Pierce examined whether race was associated with whether the death penalty was invoked in homicide cases34. Table 4.8 and Figure 4.6 summarize data on 674 defendants in indictments involving cases with multiple murders in Florida from 1976 through 1987.
| Caucasian | African American | Total | ||
|---|---|---|---|---|
| Death penalty | 53 | 15 | 68 | |
| Sentence | No death penalty | 430 | 176 | 606 |
| Total | 483 | 191 | 674 |
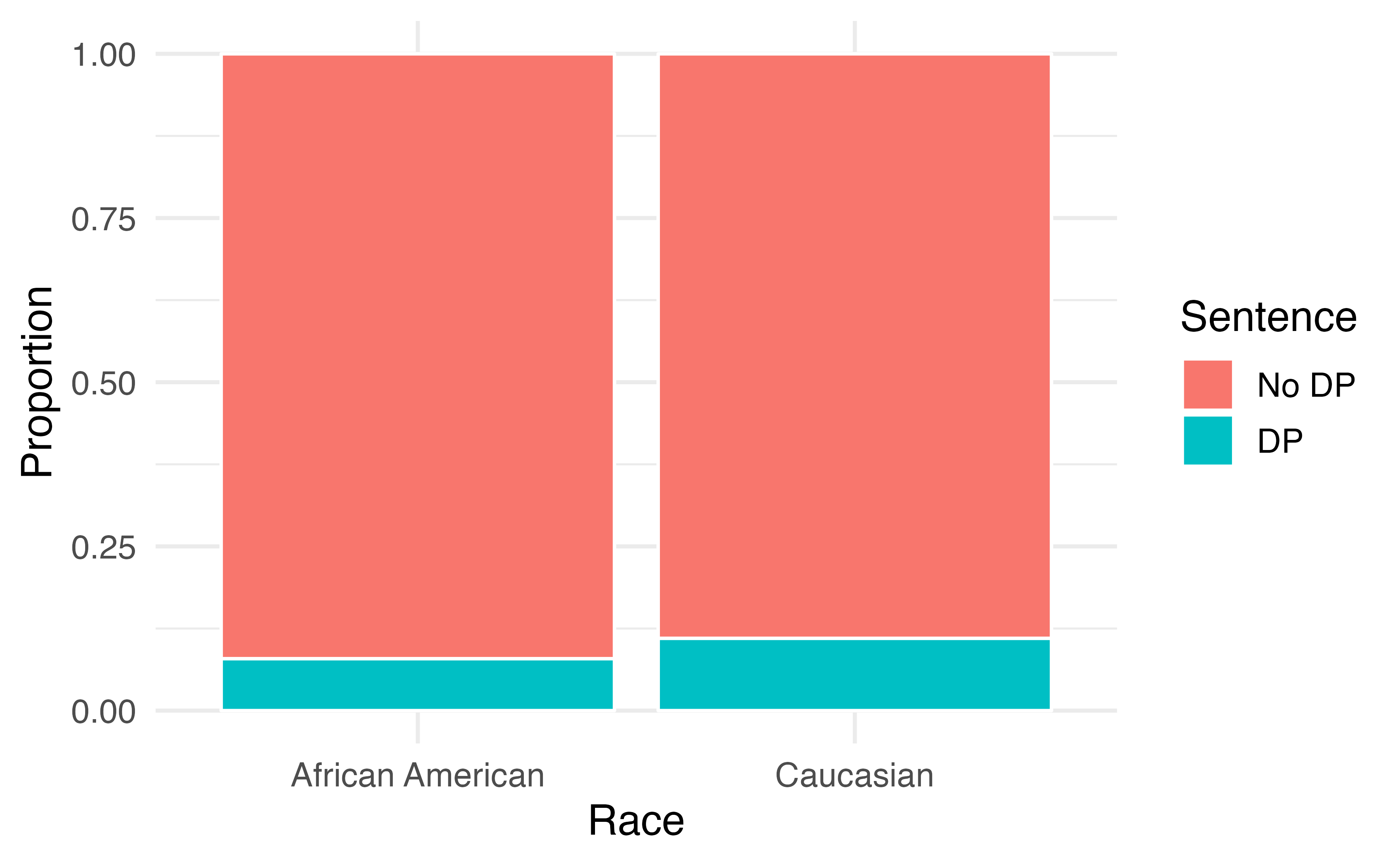
Figure 4.6: Segmented bar plot comparing the proportion of defendants who received the death penalty between Caucasians and African Americans.
Is the race of the defendant associated with the sentence of the trial?35
Overall, a lower percentage of African American defendants received the death penalty than Caucasian defendants (8% compared to 11%). Given studies have shown racial bias in sentencing, this may be surprising. Let’s look at the data more closely.
Since these are observational data, confounding variables are most likely present. Recall, a confounding variable is one that is associated with both the response variable (sentence) and the explanatory variable (race of the defendant). What confounding variables could be present?36
If we subset the data by the race of the victim, we see a different picture. Table 4.9 and Figure 4.7 summarize the same data, but separately for Caucasian and African American homicide victims.
| Victim’s race | Defendant’s race | Yes | No | Percent Yes |
|---|---|---|---|---|
| Caucasian | Caucasian | 53 | 414 | 11.3% |
| African American | 11 | 37 | 22.9% | |
| African American | Caucasian | 0 | 16 | 0.0% |
| African American | 4 | 139 | 2.8% | |
| Total | Caucasian | 53 | 430 | 11.0% |
| African American | 15 | 176 | 7.9% |
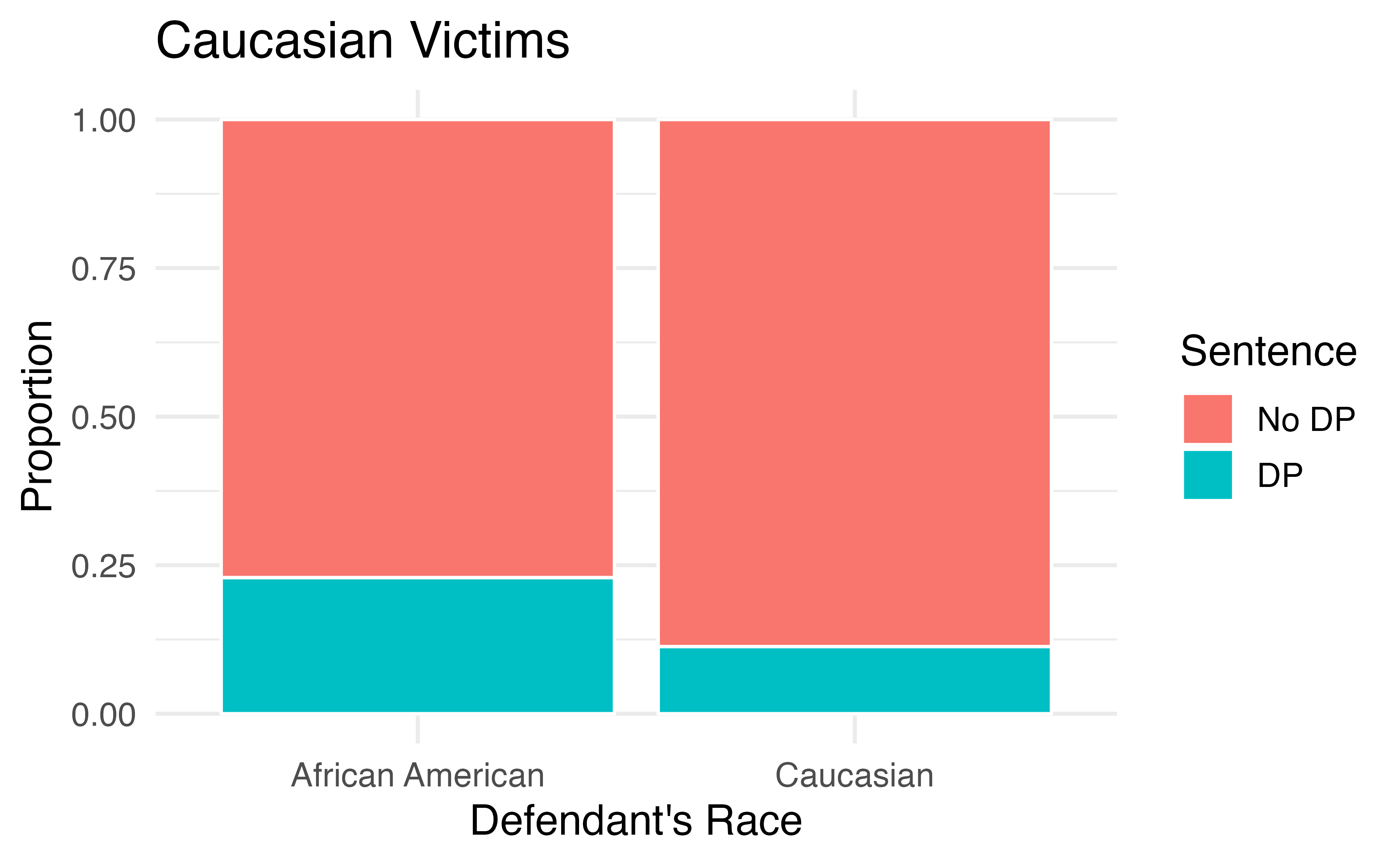
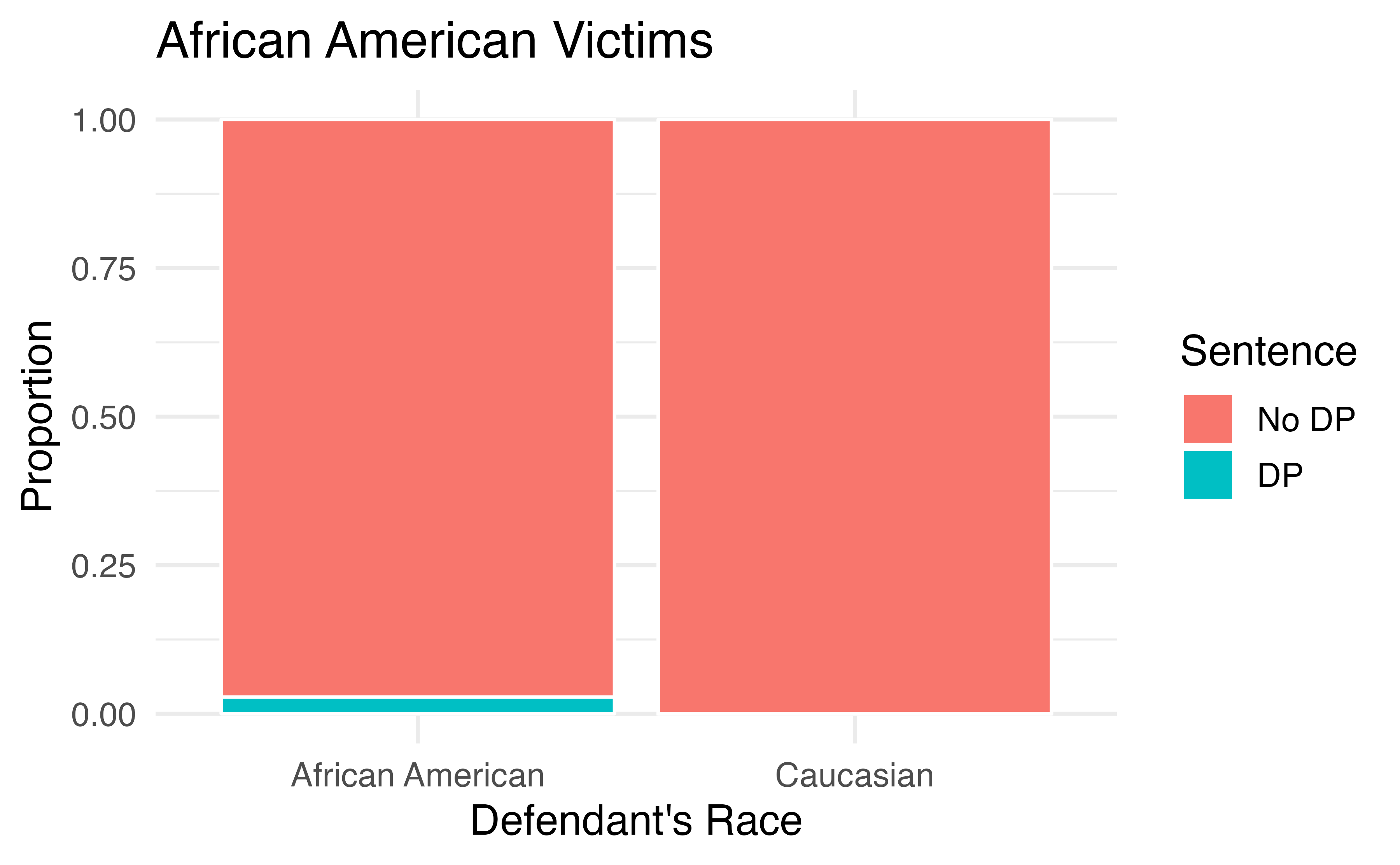
Figure 4.7: Segmented bar plots comparing the proportion of Caucasian and African American defendants who received the death penalty; separate plots for Caucasian victims and African American victims.
If we compare Figures 4.6 and 4.7, we see that the direction of the association between the race of the defendant and the sentence is reversed if we subgroup by the race of the victim. Overall, a larger proportion of Caucasians were sentenced to the death penalty than African Americans. However, when we only compare cases with the same victim’s race, a larger proportion of African Americans were sentenced to the death penalty than Caucasians!
How did this happen? The answer has to do with the race of the victim being a confounding variable. Figure 4.8 shows two segmented barplots examining the relationship between the race of the victim and the sentence (the response variable), and the relationship between the race of the victim and the race of the defendant (the explanatory variable). We see that the race of the victim is associated with both the response and the explanatory variables: defendants are more likely to involve a victim of the same race, and cases with African American victims are less likely to result in the death penalty.
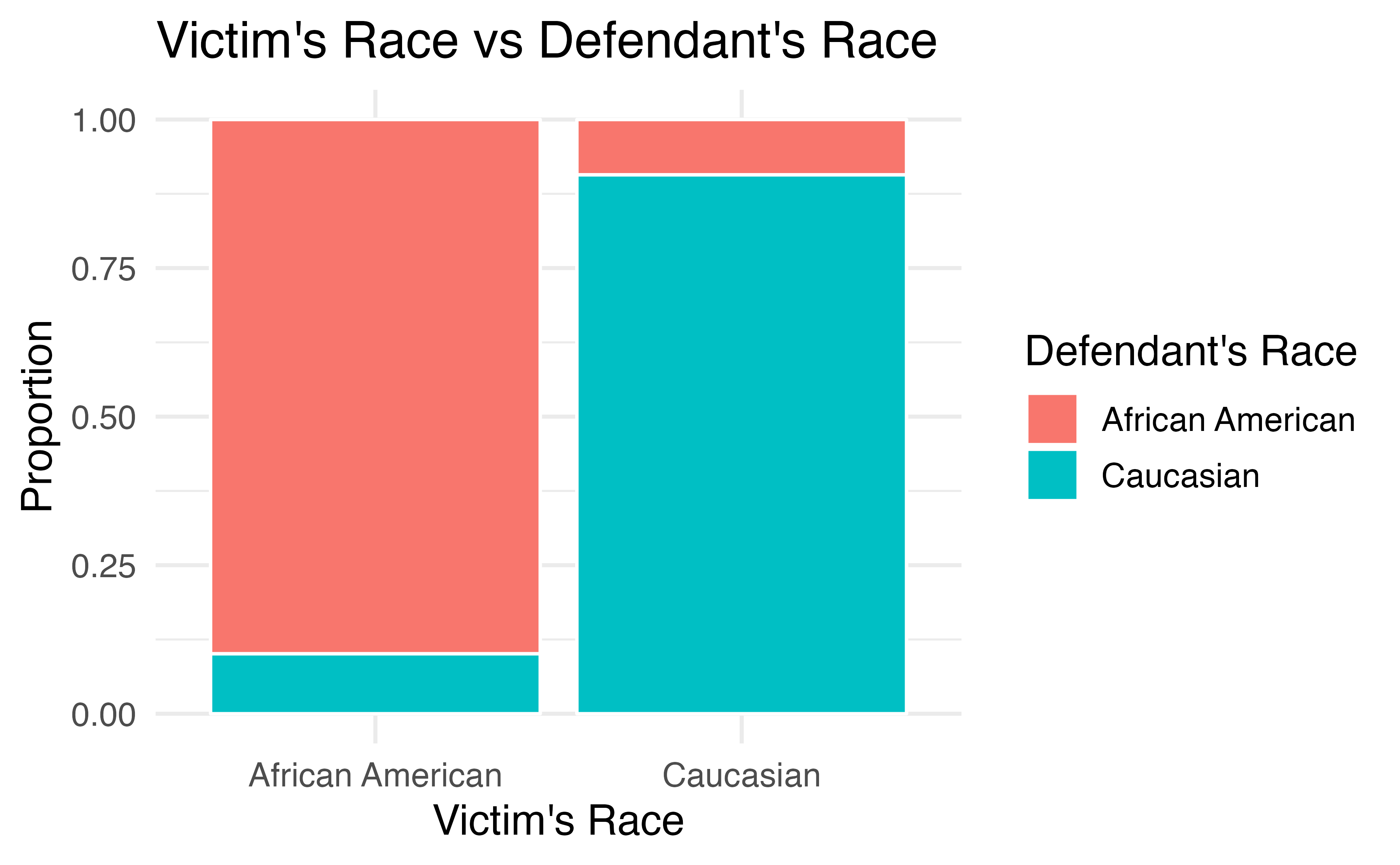

Figure 4.8: The race of the victim is associated both with the sentence (death penalty or no death penalty) and with the race of the defendant. Defendants are more likely to involve a victim of the same race, and cases with African American victims are less likely to result in the death penalty.
Thus, the extremely low chance of a homicide case resulting in the death penalty for African Americans combined with the fact that most cases with African American defendants also had an African American victim results in an overall lower rate of death penalty sentences for African American defendants than for Caucasian defendants. The overall results in Figure 4.6 and the results in each subgroup of Figure 4.7 are both valid—they are not the result of any “bad statistics”—but they suggest opposite conclusions. Data such as these, where an observed effect reverses itself when you examine the variables within subgroups, exhibit Simpson’s Paradox.
Simpson’s Paradox.
When the association between an explanatory variable and a response variable reverses itself when we examine the association within different levels of a confounding variable, we say that these data exhibit Simpson’s Paradox.
4.5 Chapter review
Summary
Fluently working with categorical variables is an important skill for data analysts. In this chapter we have introduced different visualizations and numerical summaries applied to categorical variables. The graphical visualizations are even more descriptive when two variables are presented simultaneously. We presented bar plots, mosaic plots, pie charts (and their downfalls), and estimations of conditional proportions.
Terms
We introduced the following terms in the chapter. If you’re not sure what some of these terms mean, we recommend you go back in the text and review their definitions. We are purposefully presenting them in alphabetical order, instead of in order of appearance, so they will be a little more challenging to locate. However you should be able to easily spot them as bolded text.
| association | frequency | row proportions |
| bar plot | indicator variable | row total |
| column proportions | mosaic plot | segmented bar plot |
| column total | parameter | Simpson’s Paradox |
| conditional proportion | pie chart | statistic |
| contingency table | point estimate | two-way table |
| dummy variable | relative frequency | unconditional proportion |
Key ideas
Proportions can be either unconditional or conditional. An unconditional proportion is a proportion of the entire sample that shares some characteristic; whereas a conditional proportion is a proportion of a subgroup of the sample that shares that characteristic. When computing proportions using a contingency table, unconditional proportions are computed by dividing a cell total by the overall total sample size; conditional proportions are computed by dividing a cell total by a row or column total.
The distribution of a single categorical variable can be described by examining the proportions of observations in each category.
Two variables are associated when the behavior of one variable changes with the value of the other variable. For two categorical variables, this occurs when some or all of the proportions in each category of one variable change across categories of the other variable. Recall from Chapter 1, association does not imply causation!