7 Multivariable models
The principles of simple linear regression lay the foundation for more sophisticated regression models used in a wide range of challenging settings. In this chapter, we explore the idea of “multivariable thinking” – investigating how multiple variables interact with a response variable and with each other – through a few examples. Multiple regression, which introduces the possibility of more than one predictor in a linear model, and logistic regression, a technique for predicting categorical outcomes with two levels, are presented as special topics not covered in this course.
7.1 Gapminder world
Gapminder is a “fact tank” that uses publicly available world data to produce data visualizations and teaching resources on global development. We will use an excerpt of their data to explore relationships among world health metrics across countries and regions between the years 1952 and 2007.
The gapminder data can be found in the gapminder package.
First, let’s look at the relationship between Gross Domestic Product (GDP) per capita (a measure of the wealth of a country) and Life Expectancy (in years) in the year 2007 in Figure 7.1.
![Scatterplot displaying the relationship Life Expectancy and GDP per capita in the year 2007. Note that GDP per capita is plotted on the log scale. What does each dot represent?^[Each observational unit is a single country.]](07-explore-mult-reg_files/figure-html/gdpPercap-lifeExp-1.png)
Figure 7.1: Scatterplot displaying the relationship Life Expectancy and GDP per capita in the year 2007. Note that GDP per capita is plotted on the log scale. What does each dot represent?64
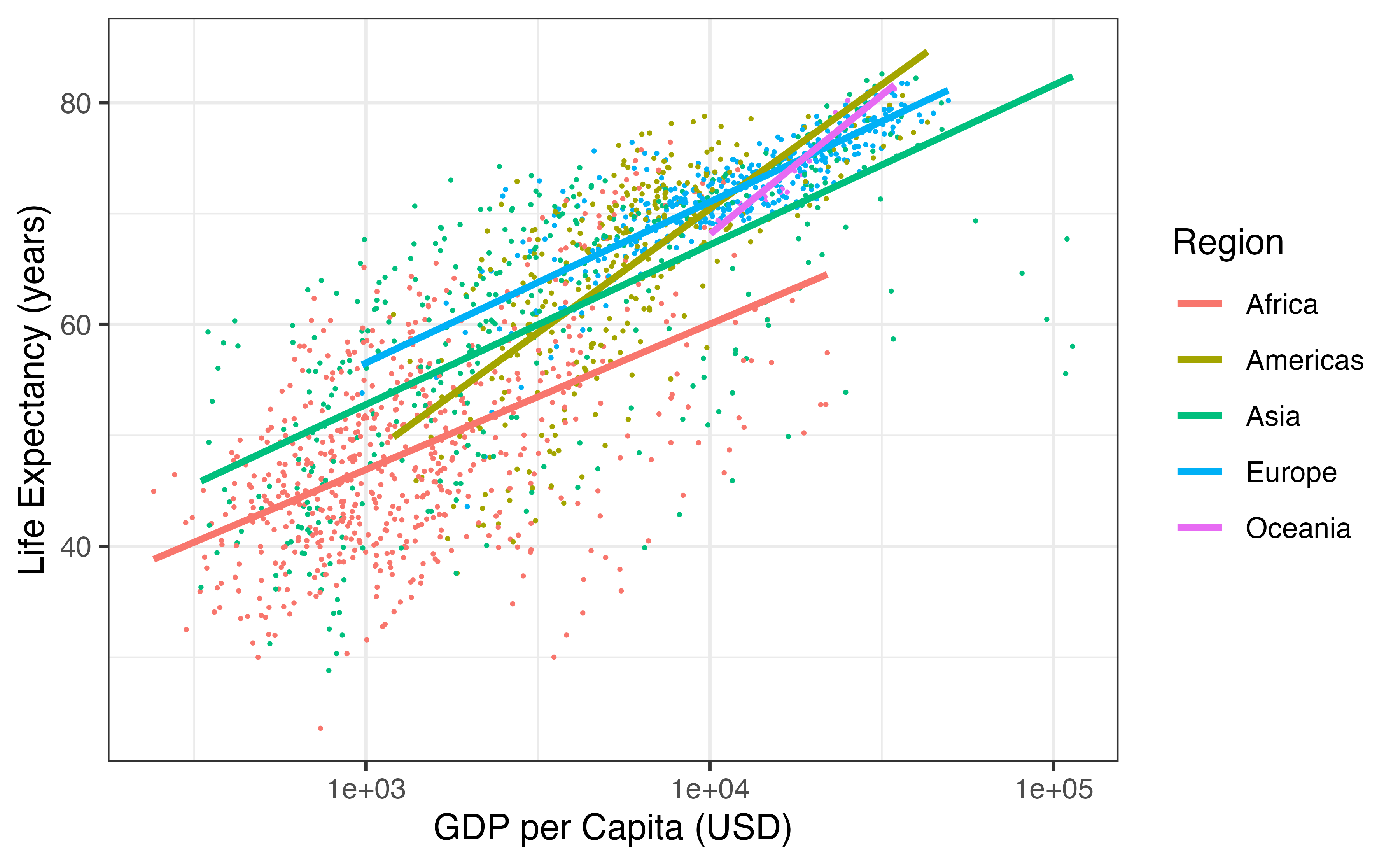
Figure 7.2: Scatterplot displaying the relationship Life Expectancy and GDP per capita by region in the year 2007. Note that GDP per capita is plotted on the log scale. Regression lines for each continent have been added.
Does the relationship between GDP per capita and life expectancy differ across regions of the world?
Yes. Looking at Figure 7.2, the five regression lines have differing slopes, telling us that the estimated change in life expectancy for a given increase in GDP per capita differs across countries. In the Americas and Oceania, life expectancy seems to rise faster with GDP per capita than the other three regions. In this case, we say that GDP per capita interacts with continent in its relationship with life expectancy.
Interaction between two explanatory variables.
If the relationship between an explanatory variable \(x\) and response variable \(y\) changes for different levels of another variable \(z\), then we say that \(x\) and \(z\) interact in their relationship with \(y\).
If \(x\) and \(y\) are quantitative, and \(z\) is categorical, as in Figure 7.2 – where \(x\) = GDP per capita, \(y\) = life expectancy, and \(z\) = continent – then if the different regression lines for each level of \(z\) have parallel slopes, we say that \(x\) and \(z\) do not interact. If the slopes are not parallel, then interaction exists between \(x\) and \(z\).
So far, we’ve explored relationships between three variables, how could we visualize relationships between five variables?65
Let’s add another variable to our plot – population. An aesthetic is a visual property of the objects in your plot. Each variable is mapped to an aesthetic. Some possible aesthetics and whether they should be used for quantitative or categorical variables are listed in Table 7.1.
| Aesthetic | Variable |
|---|---|
| Position on the x-axis as a number line | Quantitative |
| Position on the y-axis as a number line | Quantitative |
| Position on the x-axis as categories | Categorical |
| Position on the y-axis as categories | Categorical |
| Size | Quantitative |
| Color | Categorical |
| Shape | Categorical |
In Figure 7.3, quantitative variables GDP per capita, life expectancy, and population are mapped to aesthetics: position on the \(x\)-axis, position on the \(y\)-axis, and population, respectively. The categorical variable Region is mapped to color. Explore individual countries by hovering over the points.
Figure 7.3: Scatterplot displaying the relationship between four variables in the year 2007: GDP per capita (x-axis), Life Expectancy (y-axis), Population (size), and Region (color).]
How does this pattern compare to what was happening in 1952 (see Figure 7.4)?
Figure 7.4: Scatterplot displaying the relationship between four variables in the year 1952: GDP per capita (x-axis), Life Expectancy (y-axis), Population (size), and Region (color).
We can visualize relationships among four variables in the plots above (the three quantitative variables on the x- and y-axes and size, and the categorical variable as color). We could even add a fifth variable using another aesthetic, like using shape to represent the most popular religion in each country. How could we visualize what happens across time? Hans Rosling has the answer with dynamic visualization. Click on the image below to watch.

7.2 Simpson’s paradox revisited
Simpson’s Paradox was introduced in Section 4.4 through an example on race and capital punishment. In that example, all three variables of interest were categorical. In this section, we present another example of this paradox using three quantitative variables.
In 1993, respected political essayist George Will, wrote the following criticism of spending on public education in the United States.
“The 10 states with the lowest per pupil spending included four – North Dakota, South Dakota, Tennessee, Utah – among the 10 states with the top SAT scores. Only one of the 10 states with the highest per pupil expenditures – Wisconsin – was among the 10 states with the highest SAT scores. New Jersey has the highest per pupil expenditures, an astonishing $10,561, which teachers’ unions elsewhere try to use as a negotiating benchmark. New Jersey’s rank regarding SAT scores? Thirty-ninth… The fact that the quality of schools… [fails to correlate] with education appropriations will have no effect on the teacher unions’ insistence that money is the crucial variable.”
— George F. Will, September 12, 1993, “Meaningless Money Factor,” The Washington Post, C7.
George Will based his claim state expenditures, average SAT scores, and other education-based variables. These data are in the data set SAT66, the first six rows of which are displayed in Table 7.2. Variables for this data set are described in Table 7.3
| State | expend | ratio | salary | frac | verbal | math | sat | |
|---|---|---|---|---|---|---|---|---|
| 1 | Alabama | 4.41 | 17.2 | 31.1 | 8 | 491 | 538 | 1029 |
| 2 | Alaska | 8.96 | 17.6 | 48.0 | 47 | 445 | 489 | 934 |
| 3 | Arizona | 4.78 | 19.3 | 32.2 | 27 | 448 | 496 | 944 |
| 4 | Arkansas | 4.46 | 17.1 | 28.9 | 6 | 482 | 523 | 1005 |
| 5 | California | 4.99 | 24.0 | 41.1 | 45 | 417 | 485 | 902 |
| 6 | Colorado | 5.44 | 18.4 | 34.6 | 29 | 462 | 518 | 980 |
| Variable | Description |
|---|---|
| State | Name of state |
| expend | Expenditure per pupil in average daily attendance in public elementary and secondary schools, 1994-95 (in thousands of dollars) |
| ratio | Average pupil/teacher ratio in public elementary and secondary schools, Fall 1994 |
| salary | Estimated average annual salary of teachers in public elementary and secondary schools, 1994-95 (in thousands of dollars) |
| frac | Percentage of all eligible students taking the SAT, 1994-95 |
| verbal | Average verbal SAT score, 1994-95 |
| math | Average math SAT score, 1994-95 |
| sat | Average total score on the SAT, 1994-95 |
Mr. Will claims that expenditure per pupil has a negative correlation with average SAT scores across states. Is this true? Indeed, the correlation between expend and sat is equal to \(r\) = -0.381, and the relationship between the two variables is shown in Figure 7.5. Hover over each point to view data on a particular State.
Figure 7.5: Expenditure per pupil in average daily attendance in public elementary and secondary schools ($1000) verses average SAT score for the 50 states plus the District of Columbia over school year 1994-1995.
This may seem surprising, but remember – these are observational data. We cannot conclude, as George Will does, that decreasing expenditures will increase SAT scores. In fact, there is one clear confounding variable in these data: percentage of all eligible students taking the SAT.
What confounding variables may be present in this study? How could we determine whether a variable is confounding the relationship between school expenditures and SAT scores?
In some states at the time these data were collected, it was more common to take the ACT than the SAT. For students in these states, if they wanted to go to a state school, they need only take the ACT. However, if they wanted to attend college in another state, they might take the SAT. Thus, the percent of students taking the SAT in a state, frac, could be a confounding variable.
In order for frac to be confounding, it needs to be associated with our explanatory variable, expend, as well as with the response variable, sat. One could look at scatterplots and correlation between frac and expend, and between frac and sat, to determine if frac is confounding the relationship between expend and sat.
Scatterplots of expend versus frac and sat versus frac are displayed in Figure 7.6. The correlation between expend and frac is 0.593, and the correlation between sat and frac is -0.887.
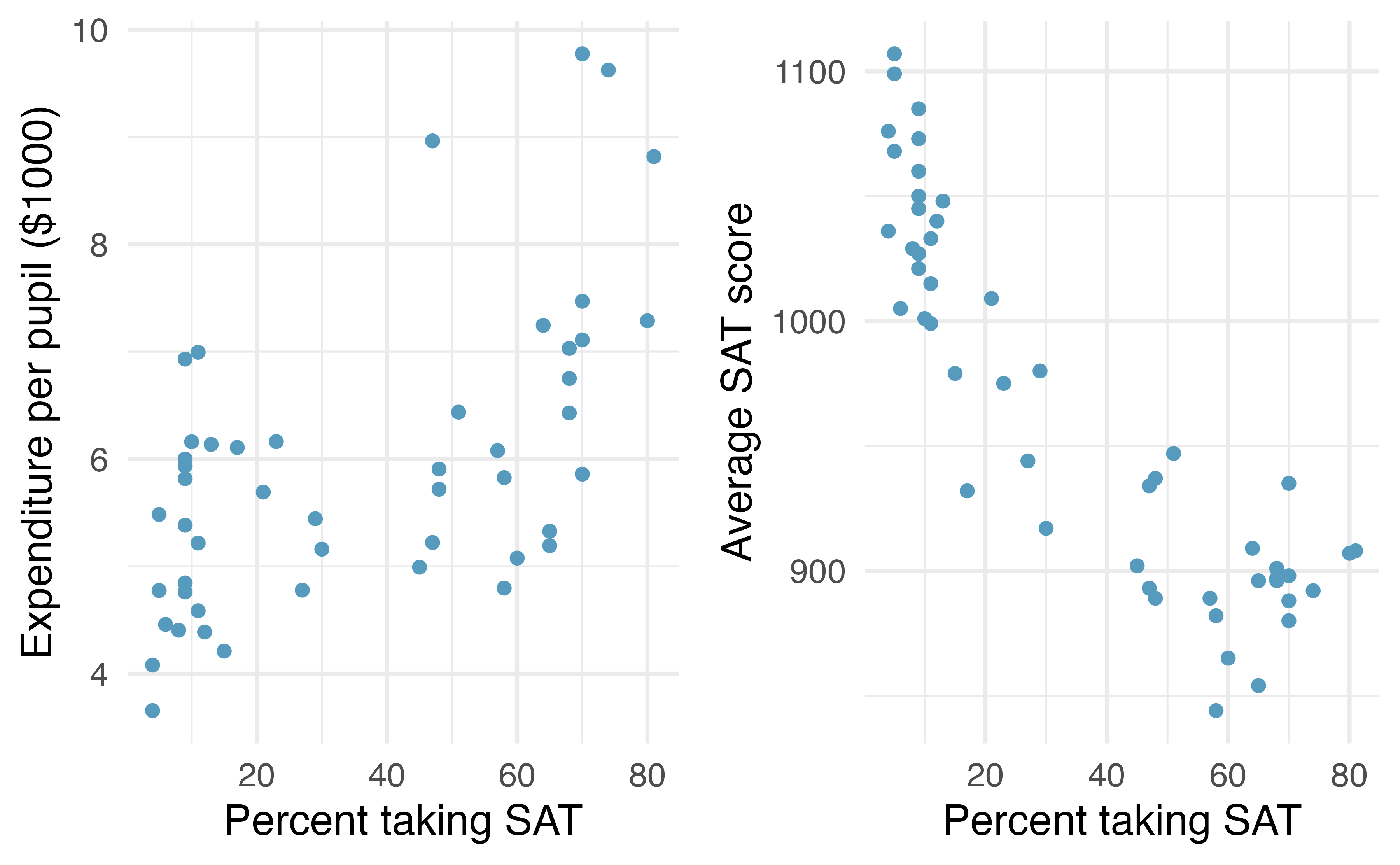
Figure 7.6: Expenditure per pupil in average daily attendance in public elementary and secondary schools ($1000) and average SAT score plotted against percent of students taking the SAT for the 50 states plus the District of Columbia over school year 1994-1995.
Now that we’ve determined that frac is a confounding variable, let’s examine if and how it modifies the relationship between expend and sat. Since it is hard to visualize three quantitative variables – 3-D scatterplots are difficult to visualize – let’s bin the variable frac into three groups. States with fewer than 15% of eligible students taking the SAT will be classified as a low percentage. States with between 15% - 55% of eligible students taking the SAT will be classified as medium Those states with more than 55% of eligible students taking the SAT will be called high. Next, we fit separate regression lines for each group. This model is shown in Figure 7.7.
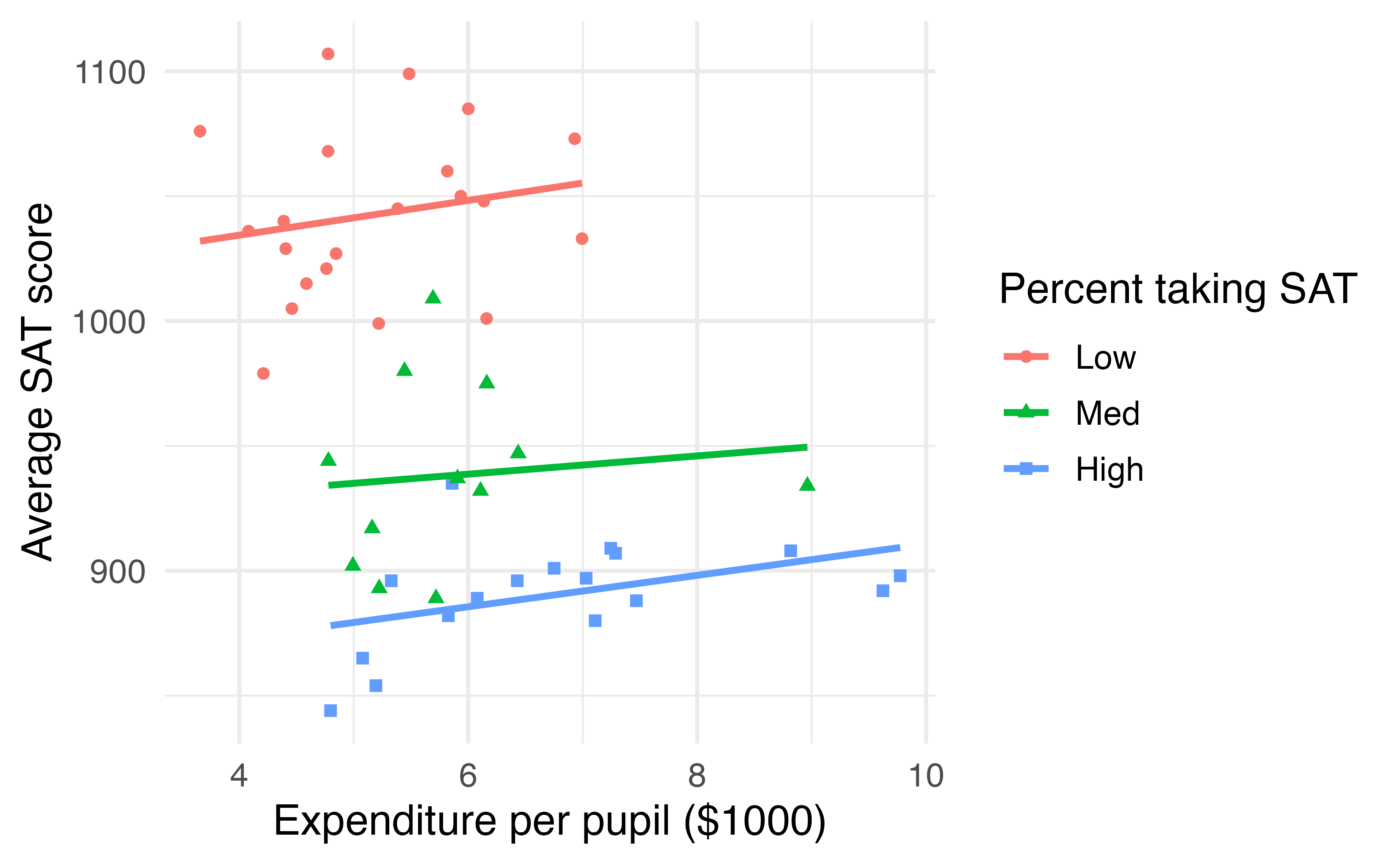
Figure 7.7: Average SAT score plotted against school expenditures per pupil, categorized by a Low (\(<\) 15%), Medium (15-55%), or High (\(>\) 55%) percent of students taking the SAT.
Figure 7.7 demonstrates that the overall negative correlation between SAT scores and expenditures disappears, and even turns slightly positive, when we examine this relationship within states with similar fractions of students taking the SAT.
Why do these data exhibit Simpson’s Paradox?67
7.3 Multiple regression (special topic)
The principles of simple linear regression lay the foundation for more sophisticated regression models used in a wide range of challenging settings. In this section, we explore multiple regression, which introduces the possibility of more than one predictor in a linear model.
Multiple regression extends simple two-variable regression to the case that still has one response but many predictors (denoted \(x_1\), \(x_2\), \(x_3\), ...). The method is motivated by scenarios where many variables may be simultaneously connected to an output.
We will consider data about loans from the peer-to-peer lender, Lending Club, which is a data set we first encountered in Chapter 1. The loan data includes terms of the loan as well as information about the borrower. The outcome variable we would like to better understand is the interest rate assigned to the loan. For instance, all other characteristics held constant, does it matter how much debt someone already has? Does it matter if their income has been verified? Multiple regression will help us answer these and other questions.
The data set includes results from 10,000 loans, and we’ll be looking at a subset of the available variables, some of which will be new from those we saw in earlier chapters.
The first six observations in the data set are shown in Table 7.4, and descriptions for each variable are shown in Table 7.5.
Notice that the past bankruptcy variable (bankruptcy) is an indicator variable, where it takes the value 1 if the borrower had a past bankruptcy in their record and 0 if not.
Using an indicator variable in place of a category name allows for these variables to be
directly used in regression.
Two of the other variables are categorical (verified_income and issue_month), each of which can take one of a few different non-numerical values; we’ll discuss how these are handled in the model in Section 7.3.1.
The data can be found in the openintro package: loans_full_schema. Based on the data in this dataset we have created to new variables: credit_util which is calculated as the total credit utilized divided by the total credit limit and bankruptcy which turns the number of bankruptcies to an indicator variable (0 for no bankrupties and 1 for at least 1 bankruptcies). We will refer to this modified dataset as loans.
| interest_rate | verified_income | debt_to_income | credit_util | bankruptcy | term | issue_month | credit_checks |
|---|---|---|---|---|---|---|---|
| 14.07 | Verified | 18.01 | 0.548 | 0 | 60 | Mar-2018 | 6 |
| 12.61 | Not Verified | 5.04 | 0.150 | 1 | 36 | Feb-2018 | 1 |
| 17.09 | Source Verified | 21.15 | 0.661 | 0 | 36 | Feb-2018 | 4 |
| 6.72 | Not Verified | 10.16 | 0.197 | 0 | 36 | Jan-2018 | 0 |
| 14.07 | Verified | 57.96 | 0.755 | 0 | 36 | Mar-2018 | 7 |
| 6.72 | Not Verified | 6.46 | 0.093 | 0 | 36 | Jan-2018 | 6 |
| variable | description |
|---|---|
| interest_rate | Interest rate on the loan, in an annual percentage. |
| verified_income |
Categorical variable describing whether the borrower’s income source and amount have been verified, with levels Verified, Source Verified, and Not Verified.
|
| debt_to_income | Debt-to-income ratio, which is the percentage of total debt of the borrower divided by their total income. |
| credit_util | Of all the credit available to the borrower, what fraction are they utilizing. For example, the credit utilization on a credit card would be the card’s balance divided by the card’s credit limit. |
| bankruptcy |
An indicator variable for whether the borrower has a past bankruptcy in their record. This variable takes a value of 1 if the answer is yes and 0 if the answer is no.
|
| term | The length of the loan, in months. |
| issue_month | The month and year the loan was issued, which for these loans is always during the first quarter of 2018. |
| credit_checks | Number of credit checks in the last 12 months. For example, when filing an application for a credit card, it is common for the company receiving the application to run a credit check. |
7.3.1 Indicator and categorical predictors
Let’s start by fitting a linear regression model for interest rate with a single predictor indicating whether or not a person has a bankruptcy in their record:
\[\widehat{\texttt{interest_rate}} = 12.33 + 0.74 \times bankruptcy\]
Results of this model are shown in Table 7.6.
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 12.338 | 0.053 | 231.49 | <0.0001 |
| bankruptcy | 0.737 | 0.153 | 4.82 | <0.0001 |
Interpret the coefficient for the past bankruptcy variable in the model. Is this coefficient significantly different from 0?
The variable takes one of two values: 1 when the borrower has a bankruptcy in their history and 0 otherwise. A slope of 0.74 means that the model predicts a 0.74% higher interest rate for those borrowers with a bankruptcy in their record. (See Section 6.2.7 for a review of the interpretation for two-level categorical predictor variables.) Examining the regression output in Table 7.6, we can see that the p-value for is very close to zero, indicating there is strong evidence the coefficient is different from zero when using this simple one-predictor model.
Suppose we had fit a model using a 3-level categorical variable, such as verified_income.
The output from software is shown in Table 7.7.
This regression output provides multiple rows for the variable.
Each row represents the relative difference for each level of verified_income.
However, we are missing one of the levels: Not Verified.
The missing level is called the reference level and it represents the default level that other levels are measured against.
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 11.10 | 0.081 | 137.2 | <0.0001 |
| verified_incomeSource Verified | 1.42 | 0.111 | 12.8 | <0.0001 |
| verified_incomeVerified | 3.25 | 0.130 | 25.1 | <0.0001 |
How would we write an equation for this regression model?
The equation for the regression model may be written as a model with two predictors:
\[ \begin{align*} \widehat{\texttt{interest_rate}} &= 11.10 + 1.42 \times \text{verified_income}_{\text{Source Verified}}\\ &\qquad\ + 3.25 \times \text{verified_income}_{\text{Verified}} \end{align*} \]
We use the notation \(\text{variable}_{\text{level}}\) to represent indicator variables for when the categorical variable takes a particular value.
For example, \(\text{verified_income}_{\text{Source Verified}}\) would take a value of 1 if
was for a loan, and it would take a value of 0 otherwise.
Likewise, \(\text{verified_income}_{\text{Verified}}\) would take a value of 1 if took a
value of verified and 0 if it took any other value.
The notation \(\text{variable}_{\text{level}}\) may feel a bit confusing.
Let’s figure out how to use the equation for each level of the verified_income variable.
Using the model for predicting interest rate from income verification type, compute the average interest rate for borrowers whose income source and amount are both unverified.
When verified_income takes a value of Not Verified, then both indicator functions in the equation for the linear model are set to 0:
\[\begin{align*} \widehat{\texttt{interest_rate}} &= 1.10 + 1.42 \times 0 \\ &\qquad\ + 3.25 \times 0 \\ &= 11.10 \end{align*}\]
The average interest rate for these borrowers is 11.1%. Because the level does not have its own coefficient and it is the reference value, the indicators for the other levels for this variable all drop out.
Using the model for predicting interest rate from income verification type, compute the average interest rate for borrowers whose income source and amount are both unverified.
When verified_income takes a value of Source Verified, then the corresponding variable takes a value of 1 while the other (\(\text{verified_income}_{\text{Verified}}\)) is 0:
\[\widehat{\texttt{interest_rate}} = 11.10 + 1.42 \times 1 + 3.25 \times 0 = 12.52\]
The average interest rate for these borrowers is 12.52%.
Compute the average interest rate for borrowers whose income source and amount are both verified.68
Predictors with several categories.
When fitting a regression model with a categorical variable that has \(k\) levels where \(k > 2\), software will provide a coefficient for \(k - 1\) of those levels. For the last level that does not receive a coefficient, this is the , and the coefficients listed for the other levels are all considered relative to this reference level.
Interpret the coefficients in the model.69
The higher interest rate for borrowers who have verified their income source or amount is surprising. Intuitively, we’d think that a loan would look less risky if the borrower’s income has been verified. However, note that the situation may be more complex, and there may be confounding variables that we didn’t account for. For example, perhaps lender require borrowers with poor credit to verify their income. That is, verifying income in our data set might be a signal of some concerns about the borrower rather than a reassurance that the borrower will pay back the loan. For this reason, the borrower could be deemed higher risk, resulting in a higher interest rate. (What other confounding variables might explain this counter-intuitive relationship suggested by the model?)
How much larger of an interest rate would we expect for a borrower who has verified their income source and amount vs a borrower whose income source has only been verified?70
7.3.2 Many predictors in a model
The world is complex, and it can be helpful to consider many factors at once in statistical modeling. For example, we might like to use the full context of borrower to predict the interest rate they receive rather than using a single variable. This is the strategy used in multiple regression. While we remain cautious about making any causal interpretations using multiple regression on observational data, such models are a common first step in gaining insights or providing some evidence of a causal connection.
We want to fit a model that accounts for not only for any past bankruptcy or whether the borrower had their income source or amount verified, but simultaneously accounts for all the variables in the loans data set: verified_income, debt_to_income, credit_util, bankruptcy, term, issue_month, and credit_checks.
\[\begin{align*} \widehat{\texttt{interest_rate}} &= b_0 + b_1\times \texttt{verified_income}_{\texttt{Source Verified}} \\ &\qquad\ + b_2\times \texttt{verified_income}_{\texttt{Verified}} \\ &\qquad\ + b_3\times \texttt{debt_to_income} \\ &\qquad\ + b_4 \times \texttt{credit_util} \\ &\qquad\ + b_5 \times \texttt{bankruptcy} \\ &\qquad\ + b_6 \times \texttt{term} \\ &\qquad\ + b_7 \times \texttt{issue_month}_{\texttt{Jan-2018}} \\ &\qquad\ + b_8 \times \texttt{issue_month}_{\texttt{Mar-2018}} \\ &\qquad\ + b_9 \times \texttt{credit_checks} \end{align*}\]
This equation represents a holistic approach for modeling all of the variables simultaneously.
Notice that there are two coefficients for verified_income and also two coefficients for issue_month, since both are 3-level categorical variables.
We estimate the coefficients in the same way as we did in the case of a single predictor—we select \(b_0\), \(b_1\), \(b_2\), \(\cdots\), \(b_9\) that minimize the sum of the squared residuals:
\[SSE = e_1^2 + e_2^2 + \dots + e_{10000}^2 = \sum_{i=1}^{10000} e_i^2 = \sum_{i=1}^{10000} \left(y_i - \hat{y}_i\right)^2\]
where \(y_i\) and \(\hat{y}_i\) represent the observed interest rates and their estimated values according to the model, respectively. 10,000 residuals are calculated, one for each observation. We typically use a computer to minimize the sum of squares and compute point estimates, as shown in the sample output in Table 7.8. Using this output, we identify the point estimates \(b_i\) just as we did in the one-predictor case.
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 1.894 | 0.210 | 9.008 | <0.0001 |
| verified_incomeSource Verified | 0.997 | 0.099 | 10.056 | <0.0001 |
| verified_incomeVerified | 2.563 | 0.117 | 21.873 | <0.0001 |
| debt_to_income | 0.022 | 0.003 | 7.434 | <0.0001 |
| credit_util | 4.897 | 0.162 | 30.249 | <0.0001 |
| bankruptcy | 0.391 | 0.132 | 2.957 | 0.0031 |
| term | 0.153 | 0.004 | 38.889 | <0.0001 |
| issue_monthJan-2018 | 0.046 | 0.108 | 0.421 | 0.6736 |
| issue_monthMar-2018 | -0.042 | 0.107 | -0.391 | 0.696 |
| credit_checks | 0.228 | 0.018 | 12.516 | <0.0001 |
Multiple regression model.
A multiple regression model is a linear model with many predictors. In general, we write the fitted model as
\[\hat{y} = b_0 + b_1 x_1 + b_2 x_2 + \cdots + b_k x_k\]
when there are \(k\) predictor variables. The coefficient estimates, \(b_0,\ldots, b_k\), are easily found using statistical software.
Write out the regression model using the point estimates from Table 7.8. How many predictors are there in this model?
The fitted model for the interest rate is given by:
\[\begin{align*} \widehat{\texttt{interest_rate}} &= 1.925 + 0.975 \times \texttt{verified_income}_{\texttt{Source Verified}} \\ &\qquad\ + 2.537 \times \texttt{verified_income}_{\texttt{Verified}} \\ &\qquad\ + 0.021 \times \texttt{debt_to_income} \\ &\qquad\ + 4.896 \times \texttt{credit_util} \\ &\qquad\ + 0.386 \times \texttt{bankruptcy} \\ &\qquad\ + 0.154 \times \texttt{term} \\ &\qquad\ + 0.028 \times \texttt{issue_month}_{\texttt{Jan-2018}} \\ &\qquad\ - 0.040 \times \texttt{issue_month}_{\texttt{Mar-2018}} \\ &\qquad\ + 0.228 \times \texttt{credit_checks} \end{align*}\]
If we count up the number of predictor coefficients, we get the effective number of predictors in the model: \(k = 9\). Notice that the categorical predictor counts as two, once for the two levels shown in the model. In general, a categorical predictor with \(p\) different levels will be represented by \(p - 1\) terms in a multiple regression model.
What does \(b_4\), the estimated coefficient of variable credit_util, represent?
What is its value?71
We estimated a coefficient for in Section 7.3.1 of \(b_4 = 0.74\) with a standard error of \(SE_{b_1} = 0.15\) when using simple linear regression. Why is there a difference between that estimate and the estimated coefficient of 0.39 in the multiple regression setting?
If we examined the data carefully, we would see that some predictors are correlated.
For instance, when we estimated the connection of the outcome interest_rate and predictor bankruptcy using simple linear regression, we were unable to control for other variables like whether the borrower had her income verified, the borrower’s debt-to-income ratio, and other variables.
That original model was constructed in a vacuum and did not consider the full context.
When we include all of the variables, underlying and unintentional bias that was missed by these other variables is reduced or eliminated.
Of course, bias can still exist from other confounding variables.
The previous example describes a common issue in multiple regression: correlation among predictor variables. We say the two predictor variables are (pronounced as co-linear) when they are correlated, and this collinearity complicates model estimation. While it is impossible to prevent collinearity from arising in observational data, experiments are usually designed to prevent predictors from being collinear.
The estimated value of the intercept is 1.925, and one might be tempted to make some interpretation of this coefficient, such as, it is the model’s predicted price when each of the variables take value zero: income source is not verified, the borrower has no debt (debt-to-income and credit utilization are zero), and so on. Is this reasonable? Is there any value gained by making this interpretation?73
7.4 Chapter review
Summary
With real data, there is often a need to describe and visualize how multiple variables can be modeled together. In this chapter, we have presented one approach using multiple linear regression. Each coefficient represents a one unit increase of that predictor variable on the response variable given the rest of the predictor variables in the model. Working with and interpreting multivariable models can be tricky, since the relationship between two variables may appear different overall than if we look at that relationship within a particular group.
Terms
We introduced the following terms in the chapter. If you’re not sure what some of these terms mean, we recommend you go back in the text and review their definitions. We are purposefully presenting them in alphabetical order, instead of in order of appearance, so they will be a little more challenging to locate. However you should be able to easily spot them as bolded text.
| aesthetic | interaction | parallel slopes |
| confounding variable | multiple regression | reference level |
Key ideas
When building data visualizations, we map different variables to different aesthetics. For example, a quantitative explanatory variable is mapped to position on the \(x\)-axis, a quantitative response variable is mapped to position on the \(y\)-axis, and a categorical variable may be mapped to color or shape of the plotting character.
A common three-variable situation is one in which we add a categorical variable to a scatterplot, by using colors and/or different point symbols. If the slope of the regression line differs across categories, we say that the relationship or association between the two quantitative variables differs across levels of the categorical variable. This is called interaction — the two explanatory variables interact in their relationship with the response variable.
Simpson’s Paradox can occur between three variables of any type (categorical or quantitative). Simpson’s Paradox occurs when the overall association between two of the variables of interest reverses when we account for a third variable. For example, overall, the slope between two quantitative variables \(x\) and \(y\) may be positive, but when we look at the slope fitted to a subset of the data in a certain category of a third variable, the slope is negative.